Table 2: Comparison metrics for the Java and Lisp versions
DNS Message Decoding
A Case Study Comparing Java and Common Lisp
By Dave Roberts
dave-at-findinglisp-dot-com
Version 1.0, 30-May-2004
I have been a Java programmer for several years, writing almost exclusively in Java for the last six years. Recently, I decided to give Common Lisp a try after reading some of the claims about increased programmer productivity and reduced development times associated with Lisp.
The last Java program I was working on was an implementation of a DNS resolver that allows a programmer access to every native DNS data time rather than just the simple address lookups provided by most TCP/IP APIs such as BSD sockets. The DNS resolver library generates DNS queries and decodes DNS responses, per RFC 1035.
As a first trial project in Common Lisp, I decided to implement a DNS resolver library. The previous Java experience was still fresh in my head and I decided that it would make an interesting comparison.
This paper compares my Java and Common Lisp implementations using several simplistic metrics.
While this comparison is too small to be statistically significant, it gives anecdotal backing to the claims that Common Lisp is more productive than other languages such as Java. This is particularly interesting in light of Java's inclusion of some Lisp features such as automatic memory management which I have personally found to be very helpful versus languages like C/C++ which have manual memory management.
Several experiments have indicated increased productivity associated with high-level languages compared with low-level languages (where “high-level” and “low-level” are defined a bit arbitrarily). Lutz Prechelt, for instance, compared C, C++, Java, Perl, Python, Rexx, and TCL [1] and found that “scripting languages” (Perl, Python, Rexx, and TCL) are more productive than “conventional languages.”
Prechelt had multiple programmers construct a solution to a common programming problem, using their choice of language from the set just described. Prechelt then analyzed the solutions, recording a number of metrics for each language, including run time, memory consumption, program length, program reliability, work time and productivity, and program structure. Prechelt found that scripting languages produced solutions to the standard problem that were one-half to one-third the length of solutions produced with the conventional language group. Further, the scripts took less then half the time to write. Note that this finding confirms the older benchmarks that suggest that programmer productivity measured in terms of lines of code produced per unit of time is roughly constant, no matter which language is used. Said in a most obvious way, people write shorter programs faster.
Erann Gatt ran a similar experiment to that conducted by Prechelt, this time comparing C, C++, Java, and Common Lisp [2]. Gatt found that Common Lisp programs took less than half the time to construct as their C, C++, and Java counterparts. Further, Gatt found that Lisp had run times that, while slower than the fastest C/C++ programs, were on average faster than the average C/C++ programs. Memory consumption for the Lisp programs was similar to that of the Java programs, both of which were larger than C/C++.
By nature, Java and Lisp foster different styles of programming. Java is very object-oriented, while Lisp is multi-paradigm, supporting functional, imperative, and object-oriented programming styles. The Resolver code written in each language reflects these fundamental differences.
The Java code uses objects
heavily. A DNS message is represented by a message, as are DNS
resource records. Each resource record type has a corresponding Java
class. The basic API expects that the user has used Java's NIO
routines to transmit a DNS request and receive a DNS reply. The DNS
UDP message data should be stored in an NIO ByteBuffer.
The Message class has a static decode
method that takes a ByteBuffer and
returns a Message object. The Message
object contains public fields that allow a client to access lists of
resource records stored in the various sections of a DNS message.
In contrast, the Lisp implementation uses a functional/imperative
programming style. Rather than have the user interface with UDP
sockets and implement timeouts and retransmissions, the Lisp
implementation uses Kevin Rosenberg's UFFI library to interface with
Linux's libresolv.so DNS library. Libresolv.so interfaces with UDP
and correctly handles retransmission of lost DNS messages. When
passed a domain name string, a DNS class code, a DNS type code, and a
pointer to a message buffer, the res_query
function returns the DNS reply message corresponding to the query
parameters in the specified buffer. The Lisp implementation uses a
small amount of code (17 lines) to interface with res_query
in the libresolv.so library. After calling res-query,
a small Lisp glue function around res_query,
the user has a UFFI byte buffer containing a raw DNS reply message.
The main Lisp decoding API is named decode-reply-message
and simply takes a UFFI buffer pointer and byte count as arguments.
The function returns a list of sub-lists representing each section of
the DNS message. Each sub-list, in turn, contains header field values
or is a list of resource records. Each resource record is encoded as
yet another list of Lisp primatives (strings, numbers, etc.).
The two implementations are functionally similar, but not fully complete. The Java version only decodes A, CNAME, MX, NS, and SOA resource records (the main resource record types that were interesting to me at the time). All other resource records are decoded as generic resource records and represented as a byte string.
The Lisp implementation decodes all RFC 1035 resource records except WKS. Any unknown resource record type (something standardized after RFC 1035, for instance) and WKS resource records are decoded as a raw list of byte values.
|
DNS Record Type |
Implemented in Java? |
Implemented in Lisp? |
|---|---|---|
|
A |
Yes |
Yes |
|
NS |
Yes |
Yes |
|
MD |
No |
Yes |
|
MF |
No |
Yes |
|
CNAME |
Yes |
Yes |
|
SOA |
Yes |
Yes |
|
MB |
No |
Yes |
|
MG |
No |
Yes |
|
MR |
No |
Yes |
|
NULL |
No |
Yes |
|
WKS |
No |
No |
|
PTR |
No |
Yes |
|
HINFO |
No |
Yes |
|
MINFO |
No |
Yes |
|
MX |
Yes |
Yes |
|
TXT |
No |
Yes |
Table 1: Resource recording types supported by each implementation
Table 1 summarizes the resource record types decoded by each implementation. Of the 16 standard record types, the Java implementation handles five while the Lisp implementation handles 15. While most of the RFC 1035 resource record types are obsolete or rarely used, the Lisp implementation is far more complete than the Java version.
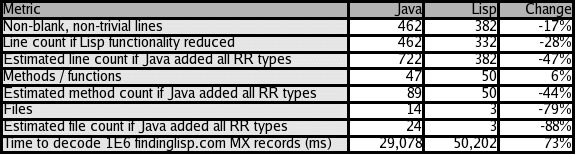
In this section, I compare the Java and Lisp implementations using a few different metrics. While the implementations are similar, there are differences that will force me to make multiple comparisons and some estimations. Table 2 shows the raw data.
Table
2: Comparison metrics for the Java and Lisp versions
First, I measured the raw line counts of the two implementations. Two small AWK scripts were written to remove blank lines and full-line comments from both the Java and Lisp versions. The Lisp version also removed documentation strings from Lisp definitions. Lines containing just a brace (“{” or “}”) in the Java version or a parenthesis (“(” or “)”) in the Lisp version were also removed (considered a trivial line of code).
The Java version was 462 lines of code while the Lisp version was 382 lines, a reduction of 17%. While the Lisp version is smaller than the Java version by 80 lines, this initial comparison neglects the difference in functionality between the two versions. The Lisp version decodes 15 of 16 resource record types and includes a UFFI interface to libresolv.so while the Java version decodes only five resource record types and does not include any code to implement the DNS transmission protocol. To correct for this, I edited the Lisp version to remove functionality that was not present in the Java version. The resulting Lisp program was 332 lines long, a reduction of 28% from the Java version.
Interestingly, the Lisp version was relatively insensitive to the number of resource records decoded. Because it is written in a largely functional style, most of the code was used to decode the primitive DNS data structures and types. Very little code was specific to the individual resource record types.
Another method of normalizing the comparison is to estimate the increase in Java code size associated with implementing the 10 extra resource record types decoded by the Lisp version. This is relatively easy to do. The average number of lines of each of the five classes implementing the A, CNAME, MX, NS, and SOA record types is 31.2. This is a bit skewed, however, because the SOA decoding is very large (50 lines). The average of the other four resource records types is 26 lines. We can estimate the number of lines to implement the other 10 resource record types as 260 lines. Adding this to the 462 lines already part of the Java implementation yields a total line count of 722. Comparing this new estimated Java line count to the 382 actual lines in the Lisp version shows the Lisp version 47% smaller than the Java version.
The next metric I used to compare the code was the number of Java methods versus the number of Lisp functions and macros. The Java code contained a total of 47 methods while the Lisp code contained 50 function and macro definitions, a small increase of 6%. Again, this neglects the functionality differences between the implementations. I measured the average number of methods in each of the five classes associated with the resource record types at 4.2. We can estimate that implementing another 10 resource record classes would require the creation of about 42 new methods, bringing the total for equivalent functionality to 89 Java methods. Comparing this new estimation to the original 50 Lisp functions and macros shows a reduction of 44% for the Lisp version.
While not really indicative of much, it is also interesting to compare the file counts. The Java version forces a file for every class because of the way that Java implements its source code structure. The total is 14 classes, or 24 if we estimate the creation of another 10 resource records to normalize the functionality. The Lisp version only has three source files. In fact, however, one of the Lisp source files is separate because of packaging conventions. Another of the Lisp source files is separate to implement a workaround for a popular Common Lisp implementation. Thus, the Lisp version could have been implemented in a single source file. Again, this comparison is for informational purposes only and doesn't necessarily say much about programmer productivity.
The final metric for comparison is run-time. I created a small loop in each version that repeatedly passed a buffer containing the result of looking up the findinglisp.com MX record to the decoding routines. The loop ran 1 million times. The Java VM implementation was Sun's 1.4.2_02 running under Linux. The Common Lisp implementation was SBCL 0.8.10 running under Linux. Both implementations ran on an AMD Athlon XP 2500+ (“Barton,” 1.8 Ghz) with Fedora Core 1 (kernel 2.4.22-1.2174.nptl). The Java version took about 29 seconds to decode the buffer 1 million times. The Lisp version took about 50 seconds to decode the buffer 1 million times, for a decoding time increase of 73% over the Java version.
Unlike the Prechelt and Gatt studies, the creation of these two implementations were not done under controlled conditions and I did not keep records of the time spent actually creating the code. In fact, there are a few factors which would skew the results even if I had kept detailed records.
I am very experienced with Java and have been writing Java code for about seven years.
I am very inexperience in writing Common Lisp code. This project was undertaken to help me learn Lisp after only a couple months of basic Lisp study on nights and weekends. It represents the first substantial program I have written in Lisp.
The Java code was written using the Eclipse IDE. Eclipse has substantial programmer automation features that assist with routine coding. For instance, a programmer can generate import statements for all classes in the current source file with a keystroke and Eclipse has a large set of refactoring commands to make major code restructuring easy.
Much of the time spent writing the Java version was consumed understanding the message coding described in RFC 1035. When writing the Lisp version, I had already absorbed most of the complexity in RFC 1035 and the only time spent reading the specification was to understand the particulars of the additional resource record types implemented in the Lisp version.
The general conclusion reached after examining the objective metrics is that Lisp is a more efficient language than Java. The Lisp version was smaller than the Java version in every instance, even when not normalizing the Java code to account for the differences in functionality. When I made estimates of the Java code size with equivalent functionality, the Lisp code was 47% smaller by line count and 44% smaller by number of functions/methods.
Generally speaking, smaller code is better code. Prechelt noted that programmer productivity measured in lines per hour is roughly constant across all programming languages in his study. If this is true, a programmer will always finish writing the smaller program first.
It is interesting to analyze exactly why the Java version is longer than the Lisp version. There are several factors that appear likely:
Java encourages object-oriented decomposition of problems, even when it may not be warranted. In this case, classes were used for DNS messages and resource records. While other decompositions could have been done in Java, this decomposition was the most “natural” and I would have had to go out of my way to generate something else. Each class in the program has a prescribed amount of overhead. Each class requires a file and at least a couple of lines for package info and class declaration. Lisp has no such requirements. It would be interesting to see if an object-oriented version using CLOS would have increased the Lisp version's size substantially.
Object-oriented decomposition forces code to be associated with a specific class. This leads to some code duplication across classes. This can be minimized through inheritance and common utility routines, but these have other trade-offs. Inheritance forces the creation of new intermediate classes with the common code. Unless the common code is large, the per-class overhead associated with the intermediate class can be a large fraction of the savings associated with centralizing the code. Utility routines may require complex interfaces since they do not necessarily have access to the private and protected data members of classes on which they operate.
Java import statements measured 26 lines alone, more than 5% of the total Java line count. Fortunately, tools like Eclipse can create these automatically and keep them updated with relatively little trouble. However, Eclipse also tends to increase the number of import statements because human programmers would be tempted to use wild-card import statements (“import package.*;”) instead of creating individual import statements for those classes actually used (“import package.class1; import package.class2;”).
Lisp supports lists as a native data type with almost seamless usage. Lists can be constructed and deconstructed with very little source code overhead. Java includes lists as a standard data type in the java.util package, but there is no special status for lists and the language syntax is not specialized to handle them well. In contrast, arrays have tighter syntax in Java than in Lisp.
Java includes type declarations. While Lisp allows a programmer to include type declarations to improve compiler efficiency, they are not mandatory. Java requires that every variable have a type. Most type declarations can be hidden in Java by declaring the type at the point of first use (“int foo = ...”). In some cases this cannot be done.
Lisp macros can eliminate large amounts of code by removing redundancy. The Lisp code makes use of a 15-line macro to eliminate upwards of 50 lines of rote coding. In certain cases, macro usage can be truly amazing, generating hundreds or even thousands of lines of code from very small programmer written source code specifications.
The only area where the Lisp program seems to fall down is with runtime performance. The Lisp code saw a 73% increase in run time versus the Java code. There are a few possible explanations for this:
First, the two programs differed slightly in how they access
the data buffer holding the DNS reply message that is being decoded.
The Java version uses a Java ByteBuffer
which wraps a standard byte array. All access to the byte array
remains in the Java runtime. The Lisp version uses UFFI deref-array
function calls to “peek” at the data one byte at a time. The
Java array accesses are probably compiled into efficient machine
code by the Sun Hotspot compiler while the deref-array
calls are macro-expanded into SBCL FFI function calls which have a
higher overhead.
Both Java and Common Lisp use garbage collection to manage memory. The decoding routines allocate lots of memory to store the decoded data items. When running in a loop of 1 million decodes, the garbage collector associated with both implementations is going to be stressed. The Sun Hotspot GC routines have been optimized extensively over two or three releases. It is not clear that SBCL has optimized its GC routines as much as the Sun Hotspot VM.
Java has strong typing. Every variable must have a type and the compiler and VM JIT are free to use this typing information to optimize runtime performance. Lisp allows the programmer to include typing information but it is not mandatory. In some cases, the Lisp compiler can use type inference to determine variable types without the programmer's help. In cases where this cannot be done and the programmer does not specify type information, the Lisp compiler must make conservative code-generation choices that preserve Lisp semantics. For instance, the compiler may be forced to call a function to perform generic arithmetic rather than use a single efficient machine instruction. The Lisp Resolver implementation uses some type declarations in the lowest-level functions but may be missing additional opportunities for optimization. A more experienced Lisp programmer may be able to do better.
Comparisons between the Java and Lisp versions of DNS message decoding support the conclusion that Lisp is a more efficient language than Java. The Lisp version was 47% smaller than the Java version when measured by line count with equivalent functionality. The Lisp version had 44% fewer functions/methods. The only area where the Lisp version did not seem better than the Java version was on runtime performance. The Lisp version had 73% greater run time than the Java version. Some of this performance difference may be attributable to factors outside of the language itself, such as implementation optimizations.
Given a constant programmer productivity across programming languages, as measured in lines of code per hour, a programmer should produce the Lisp version of the program much faster than the Java version (in almost half the time). The smaller code size should also lead to fewer defects over time.
[1] Lutz Prechelt, An empirical comparison of C, C++, Java, Perl, Python, Rexx, and Tcl, Submission to IEEE Computer, March 14, 2000. Available at http://page.mi.fu-berlin.de/~prechelt/Biblio/
[2] Erann Gat, Lisp as an alternative to Java, Intelligence 11(4): 21-24, 2000. Available at http://www.flownet.com/gat/papers/